8.2. Netzwerkprotokolle
Wir möchten Ihnen an dieser Stelle die Wikipedia-Artikel zu TCP und
UDP wärmstens empfehlen. Die folgende Darstellung ist in ihrer Struktur an
diese Artikel[33] angelehnt.
Für alle Ungeduldigen, hier eine einfache und knappe Definition: TCP
ist ein Protokoll, das sicherstellt, dass die Übertragung der gesamten
Information vom Sender geordnet und vollständig beim Empfänger ankommt.
Das Ziel der vollständigen und korrekten Datenübertragung wird mit einem
relativ großen Overhead im Verhältnis zur Nutzlast erkauft. Im Gegensatz
dazu investiert das Schwesterprotokoll UDP sehr viel weniger in die
Steuerung der Übertragung. Es schickt einfach alles raus und stellt nicht
sicher, dass jedes einzelne Datenpaket auch wirklich beim Empfänger
ankommt. Für VoIP sind beide Protokolltypen von Bedeutung, da bei einem
normalen VoIP-Anruf die initiale Verbindung über TCP hergestellt wird, die
reinen Sprachdaten aber mit UDP übertragen werden. Speziell für die
Übertragung von Audiodaten ist Quantität der Datenpakete wichtiger als
Qualität.
Transmission Control Protocol (TCP)
Das Transmission Control Protocol (TCP) ist eine Vereinbarung
(Protokoll) darüber, auf welche Art und Weise Daten zwischen Computern
ausgetauscht werden sollen. Alle Betriebssysteme moderner Computer
beherrschen TCP und nutzen es für den Datenaustausch mit anderen
Rechnern. Das Protokoll ist ein zuverlässiges, verbindungsorientiertes
Transportprotokoll in Computernetzwerken. Es ist Teil der
Internetprotokollfamilie, der Grundlage des Internets. Entwickelt wurde
TCP von Robert E. Kahn und Vinton G. Cerf. Ihre Forschungsarbeit, die
sie bereits im Jahre 1973 begannen, zog sich über mehrere Jahre hin.
Deshalb erfolgte die erste Standardisierung von TCP erst im Jahre 1981
als RFC 793. Danach gab es viele Erweiterungen, die bis heute in neuen
RFCs (einer Reihe von technischen und organisatorischen Dokumenten zum
Internet) spezifiziert werden und alle zu TCP gehören. Im Unterschied
zum verbindungslosen UDP (User Datagram Protocol) stellt TCP einen
virtuellen Kanal zwischen zwei Endpunkten einer Netzwerkverbindung
(Sockets) her. Auf diesem Kanal können in beide Richtungen Daten
übertragen werden. TCP setzt in den meisten Fällen auf das IP
(Internet-Protokoll) auf, weshalb häufig (und oft nicht ganz korrekt)
auch vom TCP/IP-Protokoll die Rede ist. Es ist in Schicht 4 des
OSI-Referenzmodells angesiedelt. Aufgrund seiner vielen angenehmen
Eigenschaften (Datenverluste werden erkannt und automatisch behoben,
Datenübertragung ist in beide Richtungen möglich, Netzwerküberlastung
wird verhindert usw.) ist TCP ein sehr weit verbreitetes Protokoll zur
Datenübertragung. Beispielsweise wird TCP als (fast) ausschließliches
Transportmedium für das WWW, E-Mail, Daten in Peer-to-Peer-Netzwerken
und für viele andere populäre Netzwerkdienste verwendet.
Allgemeines
TCP ist im Prinzip eine Ende-zu-Ende-Verbindung in Vollduplex,
die die Übertragung der Informationen in beide Richtungen zu gleicher
Zeit zulässt. Diese Verbindung kann in zwei Halbduplexverbindungen
eingeteilt werden, bei denen Informationen in beide Richtungen
(allerdings nicht gleichzeitig) fließen können. Die Daten in
Gegenrichtung können dabei zusätzliche Steuerungsinformationen
enthalten. Die Verwaltung (das Management) dieser Verbindung sowie die
Datenübertragung werden von der TCP-Software übernommen. Die
TCP-Software ist eine Funktionssammlung und (je nach Betriebssystem
unterschiedlich) bei Linux auch im Betriebssystemkern, dem
Linux-Kernel, angesiedelt. Anwendungen, die diese Software häufig
nutzen, sind zum Beispiel Webbrowser und Webserver. Jede
TCP-Verbindung wird eindeutig durch zwei Endpunkte identifiziert. Ein
Endpunkt stellt ein geordnetes Paar dar, das aus IP-Adresse und Port
besteht. Ein solches Paar bildet eine bidirektionale
Software-Schnittstelle und wird auch als Socket bezeichnet. Mithilfe
der IP-Adressen werden die an der Verbindung beteiligten Rechner
identifiziert; mithilfe der Ports werden dann auf den beiden
beteiligten Rechnern die beiden miteinander kommunizierenden Programme
identifiziert. Durch die Verwendung von Portnummern auf beiden Seiten
der Verbindung ist es beispielsweise möglich, dass ein Webserver auf
einem Port (normalerweise Port 80) gleichzeitig mehrere Verbindungen
zu einem anderen Rechner geöffnet hat. Ports sind 16-Bit-Zahlen
(Portnummern) und reichen von 0 bis 65535. Ports von 0 bis 1023 sind
reserviert und werden von der IANA vergeben. Zum Beispiel ist Port 80
für das im WWW verwendete HTTP-Protokoll reserviert. Allerdings ist
das Benutzen der vordefinierten Ports nicht bindend. So kann jeder
Administrator beispielsweise einen FTP-Server (normalerweise Port 21)
auch auf einem beliebigen anderen Port laufen lassen.
Verbindungsaufbau und -abbau
Ein Webserver, der seinen Dienst anbietet, generiert einen
Endpunkt mit dem Port und seiner Adresse. Dies wird als
passive open oder auch als
listen bezeichnet. Will ein Client eine
Verbindung aufbauen, generiert er einen eigenen Endpunkt aus seiner
Rechneradresse und einer noch freien Portnummer. Mithilfe eines ihm
bekannten Ports und der Adresse des Servers kann dann eine Verbindung
aufgebaut werden. Während der Datenübertragungsphase (active open)
sind die Rollen von Client und Server (aus TCP-Sicht) vollkommen
symmetrisch. Insbesondere kann jeder der beiden beteiligten Rechner
einen Verbindungsabbau einleiten. Während des Abbaus kann die
Gegenseite noch Daten übertragen, die Verbindung kann also halb offen
sein.
Der Drei-Wege-Handshake
Der Drei-Wege-Handshake ist die Bezeichnung für ein bestimmtes
Verfahren, um eine in Bezug auf Übertragungsverluste sichere
Datenübertragung zwischen zwei Instanzen zu ermöglichen. Obwohl er
überwiegend in der Netzwerktechnik verwendet wird, ist der
Drei-Wege-Handshake nicht auf diese beschränkt.
Verbindungsaufbau
Der Drei-Wege-Handshake kommt beim Aufbau einer TCP-Verbindung
zum Einsatz. Der Rechner, der die Verbindung aufbauen will, sendet
dem anderen Rechner ein SYN-Paket (von engl.
synchronize) mit einer Sequenznummer x. Die
Sequenznummern sind dabei für die Sicherstellung einer vollständigen
Übertragung in der richtigen Reihenfolge und ohne Duplikate wichtig.
Es handelt sich also um ein Paket, dessen SYN-Bit im Paketkopf
gesetzt ist (siehe TCP-Header). Die Start-Sequenznummer ist eine
beliebige Zahl, deren Generierung von der jeweiligen
TCP-Implementierung abhängig ist. Sie sollte jedoch möglichst
zufällig sein, um Sicherheitsrisiken zu vermeiden. Die Gegenstelle
(siehe „Aufbau des TCP-Headers“) empfängt das Paket und sendet
in einem eigenen SYN-Paket im Gegenzug ihre Start-Sequenznummer y
(die ebenfalls beliebig und unabhängig von der Start-Sequenznummer
der Gegenstelle ist). Zugleich bestätigt sie den Erhalt des ersten
SYN-Pakets, indem sie die Sequenznummer x um eins erhöht und im
ACK-Teil (von engl. acknowledgment =
Bestätigung) des Headers zurückschickt. Der Client bestätigt zuletzt
den Erhalt des SYN/ACK-Pakets durch das Senden eines eigenen
ACK-Pakets mit der Sequenznummer y+1. Dieser Vorgang wird auch als
Forward Acknowledgement bezeichnet. Außerdem
sendet der Client den Wert x+1 aus Sicherheitsgründen ebenso zurück.
Dieses ACK-Segment erhält der Server, das ACK-Segment ist durch das
gesetzte ACK-Flag gekennzeichnet. Die Verbindung ist damit
aufgebaut.
Verbindungsabbau
Der geregelte Verbindungsabbau erfolgt ähnlich. Statt des
SYN-Bits kommt das FIN-Bit (von engl. finish =
Ende, Abschluss) zum Einsatz, das anzeigt, dass keine Daten mehr vom
Sender kommen. Der Erhalt des Pakets wird wiederum mittels ACK
bestätigt. Der Empfänger des FIN-Pakets sendet zuletzt seinerseits
ein FIN-Paket, das ihm ebenfalls bestätigt wird. Obwohl eigentlich
vier Wege genutzt werden, handelt es sich beim Verbindungsabbau auch
um einen Drei-Wege-Handshake, da die ACK- und FIN-Operationen vom
Server zum Client als ein Weg gewertet werden. Zudem ist ein
verkürztes Verfahren möglich, bei dem FIN und ACK genau wie beim
Verbindungsaufbau im selben Paket untergebracht werden. Die
Maximum Segment Lifetime (MSL) ist die maximale
Zeit, die ein Segment im Netzwerk verbringen kann, bevor es
verworfen wird. Nach dem Senden des letzten ACKs wechselt der Client
in einen zwei MSL andauernden Wartezustand (Waitstate), in dem alle
verspäteten Segmente verworfen werden. Dadurch wird sichergestellt,
dass keine verspäteten Segmente als Teil einer neuen Verbindung
fehlinterpretiert werden. Außerdem wird eine korrekte
Verbindungsterminierung sichergestellt. Geht ACK y+1 verloren, läuft
beim Server der Timer ab, und das LAST_ACK-Segment wird erneut
übertragen.
Aufbau des TCP-Headers
Das TCP-Segment besteht immer aus zwei Teilen: dem
Header und der Nutzlast
(Payload). Die Nutzlast enthält die zu übertragenden Daten,
die wiederum Protokollinformationen der Anwendungsschicht wie HTTP
oder FTP entsprechen können. Der Header enthält für die Kommunikation
erforderliche Daten sowie Informationen, die das Dateiformat
beschreiben. Die Werte werden in Network Byte Order
(Big Endian) angegeben.
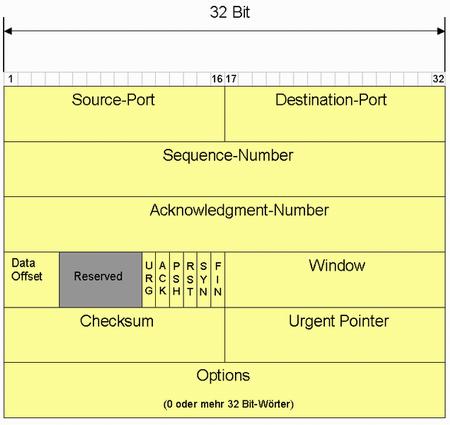
Aufbau des TCP-Headers[34]
Datenübertragung
TCP- bzw. IP-Paket-Größe
Ein TCP-Segment hat typischerweise eine Größe von 1500 Bytes.
Es darf nur so groß sein, dass es in die darunterliegende
Übertragungsschicht passt, also in das Internetprotokoll IP. Das
IP-Paket ist theoretisch bis 65.535 Bytes (64 Kilobyte)
spezifiziert, wird aber selbst meist über Ethernet übertragen, und
dort ist die Rahmengröße auf 1500 Bytes festgelegt. TCP und IP
definieren jeweils einen Header von 20 Bytes Größe. Für die
Nutzdaten bleiben in einem TCP/IP-Paket also 1460 Bytes übrig. Da
die meisten Internet-Anschlüsse DSL verwenden, gibt es dort noch das
Point-to-Point Protocol (PPP) zwischen IP und Ethernet, was noch
einmal 8 Bytes für den PPP-Rahmen kostet. Dem TCP/IP-Paket
verbleiben im Ethernet-Rahmen nur 1492 Bytes MTU (Maximum
Transmission Unit), die Nutzdaten reduzieren sich auf insgesamt 1452
Bytes MSS (Maximum Segment Size). Dies entspricht einer Auslastung
von 96,8 %.
Aufteilen der Anwendungsdaten auf TCP- bzw. IP-Pakete
Empfänger und Sender einigen sich vor dem Datenaustausch über
das Options-Feld auf die Größe der MSS. Die Anwendung, die Daten
versenden möchte, beispielsweise ein Webserver, legt zum Beispiel
einen 10 Kilobyte großen Datenblock im Puffer ab. Um so mit einem
1460 Byte großen Nutzdatenfeld 10 Kilobyte Daten zu versenden, teilt
man die Daten auf mehrere Pakete auf, fügt einen TCP-Header hinzu
und versendet die TCP-Segmente. Dieser Vorgang wird Segmentierung
genannt. Im Puffer ist der Datenblock, dieser wird in fünf Segmente
aufgeteilt. Jedes Segment erhält durch die TCP-Software einen
TCP-Header. Drei TCP-Segmente wurden aktuell abgeschickt. Diese sind
nicht notwendigerweise sortiert, da im Internet jedes TCP-Segment
einen anderen Weg nehmen und es dadurch zu Verzögerungen kommen
kann. Damit die TCP-Software im Empfänger die Segmente wieder
sortieren kann, ist jedes Segment nummeriert (die Segmente werden
sozusagen durchgezählt). Bei der Zuordnung der Segmente wird die
Sequenznummer herangezogen. Der Empfänger muss diejenigen
TCP-Segmente bestätigen, die einwandfrei (Prüfsumme ist in Ordnung)
angekommen sind.
Datenintegrität und Zuverlässigkeit
Im Gegensatz zum verbindungslosen UDP implementiert TCP einen
bidirektionalen, byte-orientierten, zuverlässigen Datenstrom zwischen
zwei Endpunkten. Das darunterliegende Protokoll (IP) ist
paketorientiert, wobei Datenpakete verloren gehen können, in
verkehrter Reihenfolge ankommen dürfen und sogar doppelt empfangen
werden können. TCP wurde entwickelt, um mit der Unsicherheit der
darunterliegenden Schichten umzugehen. Es prüft daher die Integrität
der Daten mittels der Prüfsumme im Paketkopf und stellt die
Reihenfolge durch Sequenznummern sicher. Der Sender wiederholt das
Senden von Paketen, falls keine Bestätigung innerhalb einer bestimmten
Zeitspanne (Timeout) eintrifft. Die Daten der Pakete werden beim
Empfänger in einem Puffer in der richtigen Reihenfolge zu einem
Datenstrom zusammengefügt, und doppelte Pakete werden verworfen. Der
Datentransfer kann selbstverständlich jederzeit nach dem Aufbau einer
Verbindung gestört, verzögert oder ganz unterbrochen werden. Das
Übertragungssystem läuft dann in einen Timeout. Der vorab getätigte
Verbindungsaufbau stellt also keinerlei Gewähr für eine nachfolgende,
dauerhaft gesicherte Übertragung dar.
User Datagram Protocol (UDP)
Das User Datagram Protocol (UDP) ist ein minimales,
verbindungsloses Netzprotokoll, das zur Transportschicht der
Internetprotokoll-Familie gehört. Die Aufgabe von UDP ist es, Daten, die
über das Internet übertragen werden, der richtigen Anwendung zukommen zu
lassen. Die Entwicklung von UDP begann 1977, als man für die Übertragung
von Sprache ein einfacheres Protokoll benötigte als das bisherige
verbindungsorientierte TCP. Es wurde ein Protokoll benötigt, das nur für
die Adressierung zuständig war, ohne die Datenübertragung zu sichern, da
dies zu Verzögerungen bei der Sprachübertragung führen würde.
Funktionsweise
Um die Daten, die mit UDP versendet werden, dem richtigen
Programm auf dem Zielrechner zukommen zu lassen, werden bei UDP
sogenannte Ports verwendet. Dazu wird bei UDP die Portnummer des
Dienstes mitgesendet, der die Daten erhalten soll. Diese Erweiterung
der Host-zu-Host- auf eine Prozess-zu-Prozess-Übertragung wird als
Anwendungsmultiplexen und
-demultiplexen bezeichnet.
Eigenschaften
UDP stellt einen verbindungslosen, potenziell unzuverlässigen
Übertragungsdienst bereit. Das bedeutet, dass es keine Garantie gibt,
dass ein einmal gesendetes Paket auch ankommt oder dass Pakete in der
gleichen Reihenfolge ankommen, in der sie gesendet wurden. Eine
Anwendung, die UDP nutzt, muss daher gegenüber verloren gegangenen und
umsortierten Paketen unempfindlich sein oder selbst entsprechende
Korrekturmaßnahmen beinhalten. Da vor Übertragungsbeginn nicht erst
eine Verbindung aufgebaut werden muss, können die Hosts schneller mit
dem Datenaustausch beginnen. Dies fällt vor allem bei Anwendungen ins
Gewicht, bei denen nur kleine Datenmengen ausgetauscht werden müssen.
Einfache Frage-Antwort-Protokolle wie das Domain Name
System (DNS) verwenden UDP, um die Netzwerkbelastung gering
zu halten und damit den Datendurchsatz zu erhöhen. Ein
Drei-Wege-Handshake wie bei TCP für den Aufbau der Verbindung würde
unnötigen Overhead erzeugen. Daneben bietet die ungesicherte
Übertragung auch den Vorteil von geringen
Übertragungsverzögerungsschwankungen: Geht bei einer TCP-Verbindung
ein Paket verloren, so wird es automatisch erneut angefordert. Dies
braucht Zeit, die Übertragungsdauer kann daher schwanken, was für
Multimedia-Anwendungen schlecht ist. Bei VoIP z. B. würde es zu
plötzlichen Aussetzern kommen bzw. die Wiedergabepuffer müssten größer
angelegt werden. Bei verbindungslosen Kommunikationsdiensten bringen
verloren gegangene Pakete dagegen nicht die gesamte Übertragung ins
Stocken, sondern vermindern lediglich die Qualität. UDP übernimmt die
Eigenschaften der darunterliegenden Netzwerkschicht. Im Falle des
Internetprotokolls IP können Datenpakete maximal 65.535 Bytes lang
sein, wovon der IP-Header und UDP-Header insgesamt mindestens 28 Bytes
belegen. UDP-Datagramme haben daher maximal 65.507 Nutzdatenbytes.
Solche Pakete werden jedoch von IP fragmentiert übertragen, sodass UDP
nur bei Datenpaketgrößen bis zu einigen Kilobytes sinnvoll ist. IP
löscht Pakete etwa bei Übertragungsfehlern oder bei Überlast.
Datagramme können daher fehlen. Das UDP-Protokoll bietet hierfür keine
Erkennungs- oder Korrekturmechanismen wie etwa TCP. Im Falle von
mehreren möglichen Routen zum Ziel kann IP bei Bedarf neue Wege
wählen. Hierdurch ist es in seltenen Fällen sogar möglich, dass später
gesendete Daten früher gesendete überholen.